@INPROCEEDINGS{mannist,
AUTHOR = "S. Mann",
TITLE = "Compositing Multiple Pictures of the Same Scene",
Organization = {The Society of Imaging Science and Technology},
BOOKTITLE = {Proceedings of the 46th Annual {IS\&T} Conference},
Address = {Cambridge, Massachusetts},
Month = {May 9-14},
pages = "50--52",
note = "ISBN: 0-89208-171-6",
YEAR = {1993}
}
has recently been published in more detail in:
@techreport{manntip,
author = "S. Mann and R. W. Picard",
title = "Video orbits of the projective group;
A simple approach to featureless estimation of parameters",
institution = "Massachusetts Institute of Technology",
type = "TR",
number = "338",
address = "Cambridge, Ma",
month = "See http://n1nlf-1.eecg.toronto.edu/tip.ps.gz",
note = "Also appears {IEEE} Trans. Image Proc., Sept 1997, Vol. 6 No. 9",
year = 1995}
(The aspect of the 1993 paper dealing with differently exposed pictures
to appear in a later Proc IEEE paper; please contact author of this
WWW page if you're
interested in knowing more about extending dynamic range by combining
differently exposed pictures, or getting a preprint.)
The new algorithm is applied to the task of constructing high resolution still images from video. This approach generalizes inter-frame camera motion estimation methods which have previously used an affine model and/or which have relied upon finding points of correspondence between the image frames.
The new method, which allows an image to be created by ``painting with video'' is used in conjunction with a wearable wireless webcam, so that image mosaics can be generated simply by looking around, in a sense, ``painting with looks''.
 Example of image composite from IS&T 1993 paper
(click to see higher resolution version).
In the above example, the spatial extent of the
image is increased by panning the camera while mosaicing
and the spatial resolution is increased by
zooming the camera and by combining overlapping frames from different
viewpoints.
Example of image composite from IS&T 1993 paper
(click to see higher resolution version).
In the above example, the spatial extent of the
image is increased by panning the camera while mosaicing
and the spatial resolution is increased by
zooming the camera and by combining overlapping frames from different
viewpoints.
Note that the author overran the panning to appear twice in the composite picture (this is an old trick dating back to the days of the 1904 Kodak circuit 10 camera which is still used to take the freshman portraits in Killian court, and there are several people who still overrun the camera to get in the picture twice). Note also that the author appears sharper on the right than on the left because of the zooming in (``saliency'') at that region of the image.
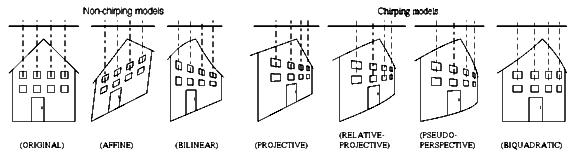
Note also that, unlike previous methods based on the affine model, the inserts are not parallelogram-shaped (e.g. not affine), because a projective (homographic) coordinate transformation is used here rather than the affine coordinate transformation.
The difference between the affine model and the projective model
is evident in the following figure:
For completeness, other coordinate transformations, such as bilinear and pseudo-perspective, are also shown. Note that the models are presented in two categories, models that exhibit the ``chirping'' effect, and those that do not.
 Click for medium-resolution greyscale image;
a somewhat higher resolution image is available
here;
a much higher resolution version of this same picture, in either 192 bit
color (double) or 24 bit color (uchar), is available upon request).
Click for medium-resolution greyscale image;
a somewhat higher resolution image is available
here;
a much higher resolution version of this same picture, in either 192 bit
color (double) or 24 bit color (uchar), is available upon request).
{kind=link}